nCache Heliosearch has a new replacement for the Lucene FieldCache currently used by Solr for sorting, faceting, and function queries. Introducing nCache (n is for “native”): nCache has Off-Heap Data-structures, just like the Off-Heap Filters to lower garbage collection pauses and GC overhead. nCache is a managed cache, meaning […]
yonik
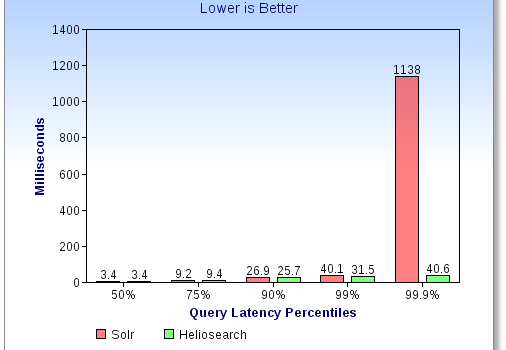
Off-Heap Native Filters is the first feature we added to Heliosearch, a new open source project designed to bring Solr performance to the next level. Big JVM heaps can be Big Trouble JVMs have never been good at dealing with large heaps. Large heaps mean lots of garbage collection work, […]
Heliosearch/Solr Off-Heap Filters
The Solr 5 Tutorial is Here Getting Started with Solr: a Simple Solr Tutorial Note: this tutorial is for Solr 4 1. Download Solr Download Apache Solr 4. You only need to download the single .ZIP or .TGZ file and extract it anywhere you like – no installation is required!! […]
Getting Started with Solr
The filter caching features in Solr allow for precise control over how filter queries are handled in order to maximize performance. Solr has the ability to specify if a filter is cached, specify the order filters are evaluated, and specify post filtering. Solr Filter Queries Adding a filter expressed as […]
Advanced Filter Caching in Solr
Background I needed a really good hash function for the distributed indexing in SolrCloud. Since it is be used for partitioning documents, it needed to be really high quality (well distributed) since we don’t want uneven shards. It also needed to be cross-platform, so a client could calculate this hash […]
MurmurHash3 for Java
Solr took another step toward increasing it’s NoSQL datastore capabilities, with the addition of realtime get. Background As readers probably know, Lucene/Solr search works off of point-in-time snapshots of the index. After changes have been made to the index, a commit (or a new Near Real Time softCommit) needs to […]
Solr’s Realtime Get
Lucene’s default ranking function uses factors such as tf, idf, and norm to help calculate relevancy scores. Solr has now exposed these factors as function queries. docfreq(field,term) returns the number of documents that contain the term in the field. termfreq(field,term) returns the number of times the term appears in the […]
Solr relevancy function queries
I previously introduced Solr’s Result Grouping, also called Field Collapsing, that limits the number of documents shown for each “group”, normally defined as the unique values in a field or function query. Since then, there have been a number of bug fixes, performance improvements, and feature enhancements. You’ll need a […]
Solr Result Grouping / Field Collapsing Improvements
Solr has been able to produce JSON results for a long time, by adding wt=json to any query. A new capability has recently been added to allow indexing in JSON, as well as issuing other update commands such as deletes and commits. All of the functionality that was available through […]
Indexing JSON in Solr 3.1
Result Grouping, also called Field Collapsing, has been committed to Solr! This functionality limits the number of documents for each “group”, usually defined by the unique values in a field (just like field faceting). You can think of it like faceted search, except instead of just getting a count, you […]